Friendli Engine
About Friendli Engine
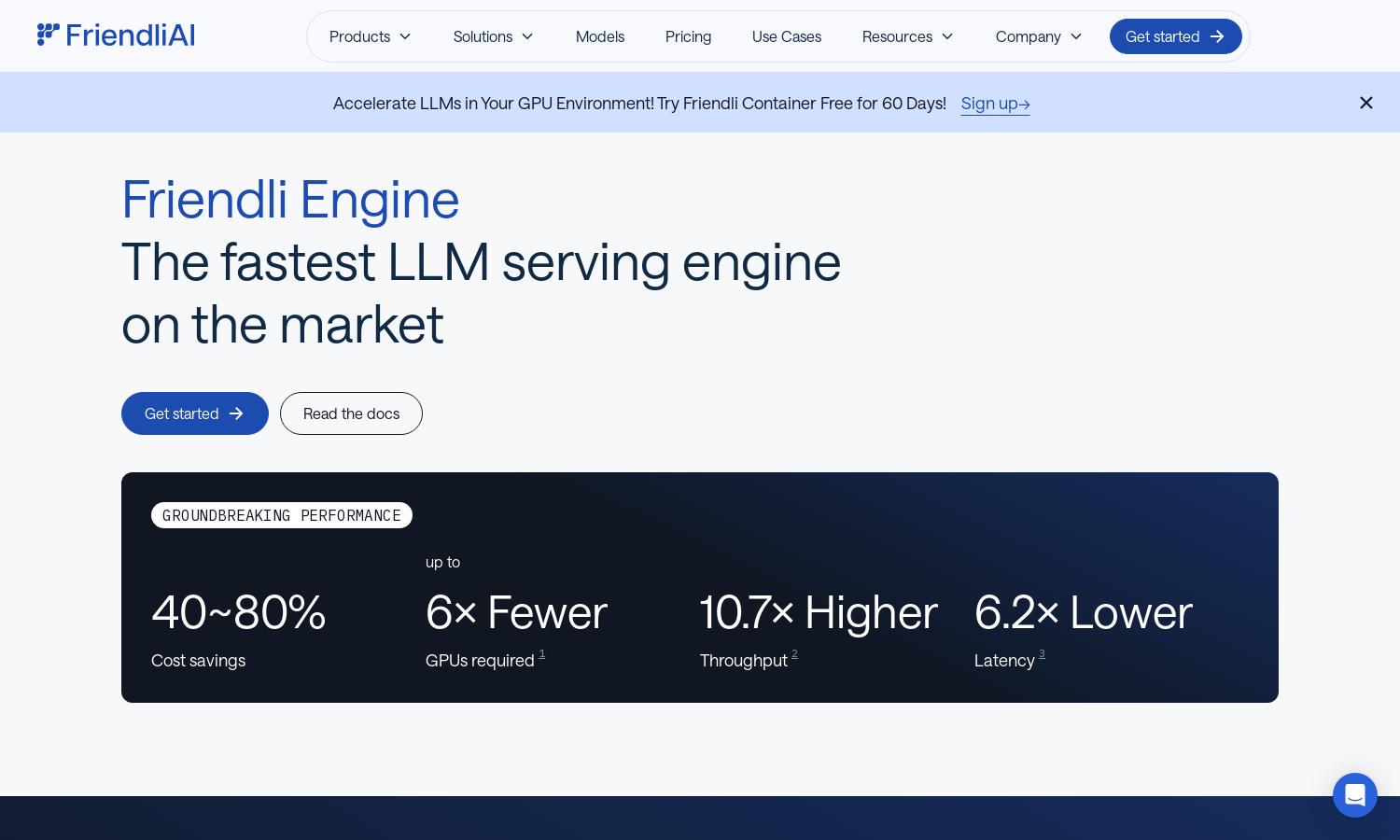
Friendli Engine is revolutionizing LLM inference with unmatched speed and cost savings. Targeted at developers and businesses in generative AI, its innovative features like iteration batching and efficient GPU utilization allow for rapid model deployment and improved performance. This makes LLM customization accessible and economical.
Friendli Engine offers flexible pricing plans designed to accommodate various user needs. Each tier provides unique features optimized for LLM inference, with significant cost savings highlighted. Users can benefit from special discounts for upgrading, ensuring they receive maximum value for their investment in generative AI technologies.
Friendli Engine boasts a user-friendly interface that simplifies navigation and interaction. Its layout supports seamless browsing, allowing users to quickly access features such as model deployment and inference monitoring. This design enhances the overall user experience, making Friendli Engine an efficient choice for working with generative AI models.
How Friendli Engine works
Users start by signing up for Friendli Engine, followed by selecting the desired generative AI model to deploy. They can effortlessly navigate through dedicated endpoints, containers, or serverless options to serve LLM inferences. The platform’s unique features, such as iteration batching and optimized GPU use, ensure powerful and efficient model performance from the get-go.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine's iteration batching technology allows for unparalleled efficiency in handling concurrent generation requests. This innovative feature enables users to achieve up to tens of times higher LLM inference throughput, making it a key offering that enhances speed and performance in generative AI applications.
Multi-LoRA Model Support
Friendli Engine supports simultaneous multi-LoRA model serving on fewer GPUs, greatly enhancing accessibility and efficiency in LLM customization. This feature reduces hardware costs and allows users to deploy diverse models, maximizing their computational resources while ensuring the performance remains top-notch.
Friendli TCache
Friendli TCache intelligently caches frequently used computational results, resulting in a significant reduction in GPU workload. This unique feature of Friendli Engine optimizes Time to First Token (TTFT), enabling users to achieve faster responses and improved efficiency in their generative AI tasks.








