Agenta
Agenta is an open-source LLMOps platform that centralizes prompt management, evaluation, and observability for AI teams.
Visit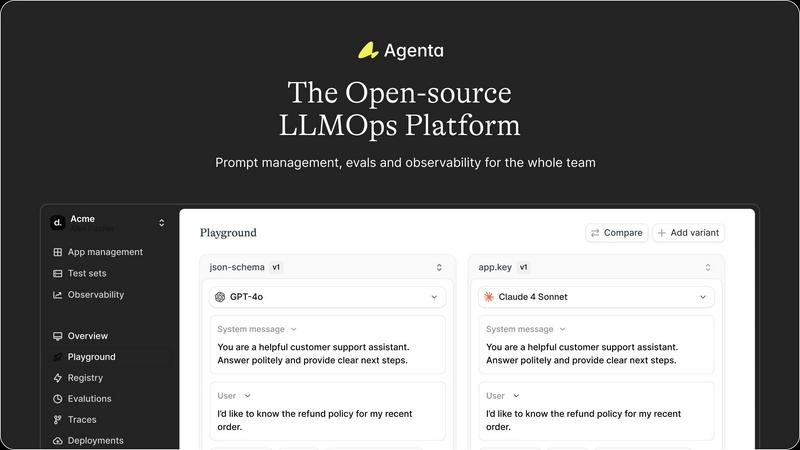
About Agenta
Agenta is an innovative open-source LLMOps platform crafted to revolutionize the way AI teams build and deploy reliable large language model (LLM) applications. Designed specifically for developers and subject matter experts, Agenta streamlines collaboration across teams, addressing the chaos often associated with LLM projects. It centralizes the development process by integrating prompt management, evaluation, and observability into a single platform. The unpredictable nature of LLMs can scatter workflows and create silos among teams. Agenta breaks down these barriers, allowing for efficient experimentation with prompts, comprehensive evaluations, and effective debugging of production issues. By transforming scattered workflows into structured processes, Agenta enables teams to enhance performance, reduce guesswork in debugging, and accelerate the delivery of reliable AI applications. With Agenta, every team member can contribute effectively, ensuring best practices are followed throughout the LLM development lifecycle.
Features of Agenta
Centralized Workspace
Agenta provides a unified platform to store all prompts, evaluations, and traces, eliminating the fragmentation of tools. This centralization fosters collaboration and ensures that everyone on the team has access to the same information, enhancing communication and efficiency.
Unified Playground
The platform features a comprehensive playground where teams can experiment and iterate on prompts side-by-side. With complete version history, users can track changes and compare different models, making it easier to identify the best-performing solutions without vendor lock-in.
Automated Evaluation
Agenta offers systematic automated evaluations that allow teams to run experiments, track results, and validate every change made. By integrating any evaluator, whether built-in or custom, it replaces guesswork with data-driven insights, ensuring informed decision-making.
Observability Tools
The observability features of Agenta enable teams to trace every request, pinpoint failure points, and annotate traces collaboratively. This functionality transforms feedback into actionable insights, allowing for quick debugging and continuous improvement of AI systems.
Use Cases of Agenta
Collaborative LLM Development
Agenta is ideal for teams working on LLM applications who need a structured way to collaborate. By centralizing prompt management and evaluation, teams can work together effectively, reducing miscommunication and enhancing productivity.
Iterative Prompt Testing
Teams can utilize Agenta to rapidly iterate on prompts in a controlled environment. With the unified playground, developers can test multiple variations and quickly identify which prompts yield the best results, accelerating the development cycle.
Performance Monitoring
Agenta allows teams to monitor production systems in real-time, helping to detect regressions and performance issues as they arise. This proactive monitoring ensures that any problems are addressed promptly, maintaining the quality of AI applications.
User Feedback Integration
By utilizing Agenta's trace annotation features, teams can gather valuable user feedback directly within the platform. This integration helps teams refine their models based on real-world usage, enhancing the overall effectiveness of their LLM applications.
Frequently Asked Questions
What is LLMOps?
LLMOps refers to a set of practices and tools designed to optimize the development and deployment of large language models (LLMs). Agenta embodies LLMOps principles by providing a structured platform for collaboration, experimentation, and observability.
How does Agenta improve collaboration among team members?
Agenta centralizes workflows by integrating prompt management, evaluation, and observability into a single platform. This eliminates silos, allowing developers, product managers, and domain experts to work together more efficiently.
Can Agenta integrate with existing tools?
Yes, Agenta is designed to seamlessly integrate with various frameworks and models, including LangChain and OpenAI. This flexibility allows teams to incorporate Agenta into their existing tech stack without disruption.
Is Agenta suitable for both developers and non-technical users?
Absolutely. Agenta's user interface is designed to empower domain experts and product managers to run evaluations and experiment with prompts without needing to write code. This inclusivity enhances collaboration across diverse team members.
Explore more in this category:
Similar to Agenta
TheToolsVerse is an AI tools directory that helps users discover, compare, and find the best AI tools for productivity, content creation, coding, mark
MCPize is a marketplace where developers can discover, install, and manage 1,000+ premium MCP servers while publishers keep 80% of revenue.
Agyn is the open-source platform that lets teams ship and manage secure AI agents with built-in access control, budgets, and policy enforcement.
act101 is a lightning-fast Rust binary that lets AI agents instantly refactor and port code across 163 languages with zero setup or data leaks.