Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right product.
Agenta is an open-source LLMOps platform that centralizes prompt management, evaluation, and observability for AI teams.
Last updated: March 1, 2026
OpenMark AI benchmarks over 100 LLMs for your specific tasks, delivering instant insights on cost, speed, quality, and stability.
Last updated: March 26, 2026
Visual Comparison
Agenta
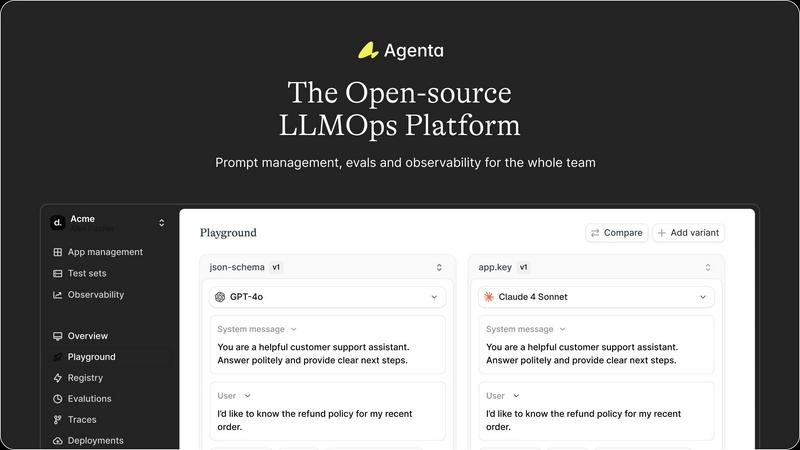
OpenMark AI

Feature Comparison
Agenta
Centralized Workspace
Agenta provides a unified platform to store all prompts, evaluations, and traces, eliminating the fragmentation of tools. This centralization fosters collaboration and ensures that everyone on the team has access to the same information, enhancing communication and efficiency.
Unified Playground
The platform features a comprehensive playground where teams can experiment and iterate on prompts side-by-side. With complete version history, users can track changes and compare different models, making it easier to identify the best-performing solutions without vendor lock-in.
Automated Evaluation
Agenta offers systematic automated evaluations that allow teams to run experiments, track results, and validate every change made. By integrating any evaluator, whether built-in or custom, it replaces guesswork with data-driven insights, ensuring informed decision-making.
Observability Tools
The observability features of Agenta enable teams to trace every request, pinpoint failure points, and annotate traces collaboratively. This functionality transforms feedback into actionable insights, allowing for quick debugging and continuous improvement of AI systems.
OpenMark AI
Task Description Flexibility
OpenMark AI allows users to describe their benchmarking tasks in plain language, making it accessible for users of all technical backgrounds. This flexibility ensures that even those with limited coding experience can effectively engage with the platform and initiate meaningful comparisons between different AI models.
Real-time Model Comparison
With OpenMark AI, you can run tests against over 100 models simultaneously and receive side-by-side results based on actual API calls, not cached data. This feature guarantees that users can make data-driven decisions based on real performance metrics, providing clarity on which model truly excels for specific tasks.
Cost and Performance Analysis
The platform highlights cost efficiency by detailing the actual cost associated with each API call. Users can evaluate which model provides the best quality relative to its price, rather than just selecting the cheapest option. This analysis is crucial for teams that prioritize budgeting alongside model performance.
Consistency Assessment
OpenMark AI enables users to assess the consistency of model outputs by running the same task multiple times. This feature is essential for teams that need reliable performance from AI models, allowing them to identify models that deliver stable, repeatable results, which is vital for maintaining quality across applications.
Use Cases
Agenta
Collaborative LLM Development
Agenta is ideal for teams working on LLM applications who need a structured way to collaborate. By centralizing prompt management and evaluation, teams can work together effectively, reducing miscommunication and enhancing productivity.
Iterative Prompt Testing
Teams can utilize Agenta to rapidly iterate on prompts in a controlled environment. With the unified playground, developers can test multiple variations and quickly identify which prompts yield the best results, accelerating the development cycle.
Performance Monitoring
Agenta allows teams to monitor production systems in real-time, helping to detect regressions and performance issues as they arise. This proactive monitoring ensures that any problems are addressed promptly, maintaining the quality of AI applications.
User Feedback Integration
By utilizing Agenta's trace annotation features, teams can gather valuable user feedback directly within the platform. This integration helps teams refine their models based on real-world usage, enhancing the overall effectiveness of their LLM applications.
OpenMark AI
Model Selection for Product Development
Product teams can utilize OpenMark AI to benchmark various models against specific tasks related to their applications. This ensures that they select the most suitable model to enhance their product features, ultimately leading to better user experiences and higher satisfaction.
Cost-Benefit Analysis for AI Implementation
Businesses can leverage OpenMark AI to perform a detailed cost-benefit analysis of different AI models. By comparing performance metrics alongside pricing, organizations can make informed decisions about which AI solution offers the best value for their particular needs, maximizing their return on investment.
Research and Development Optimization
Research teams can use OpenMark AI to test various language models for data extraction, classification, and other tasks. This capability allows them to identify the most effective models for their research projects, streamlining the development process and yielding higher quality results.
Quality Assurance for AI Outputs
Quality assurance teams can implement OpenMark AI to ensure the AI models they are using produce consistent and accurate results. By benchmarking the models against predefined tasks, QA teams can establish a solid feedback loop, allowing for continuous improvement of AI implementations.
Overview
About Agenta
Agenta is an innovative open-source LLMOps platform crafted to revolutionize the way AI teams build and deploy reliable large language model (LLM) applications. Designed specifically for developers and subject matter experts, Agenta streamlines collaboration across teams, addressing the chaos often associated with LLM projects. It centralizes the development process by integrating prompt management, evaluation, and observability into a single platform. The unpredictable nature of LLMs can scatter workflows and create silos among teams. Agenta breaks down these barriers, allowing for efficient experimentation with prompts, comprehensive evaluations, and effective debugging of production issues. By transforming scattered workflows into structured processes, Agenta enables teams to enhance performance, reduce guesswork in debugging, and accelerate the delivery of reliable AI applications. With Agenta, every team member can contribute effectively, ensuring best practices are followed throughout the LLM development lifecycle.
About OpenMark AI
OpenMark AI is a cutting-edge web application designed specifically for task-level benchmarking of large language models (LLMs). Its intuitive interface allows users to describe their testing requirements in plain language, enabling them to run identical prompts across multiple AI models in a single session. This comprehensive approach not only facilitates the assessment of cost per request and latency but also evaluates scored quality and stability through repeated runs. By providing a clear view of variance rather than relying on a single output, OpenMark AI empowers developers and product teams to make informed decisions when selecting or validating AI models before deployment. The platform eliminates the hassle of managing separate API keys for different models, as it utilizes hosted benchmarking through credit usage. With a focus on cost efficiency and consistent output quality, OpenMark AI is the go-to solution for teams aiming to optimize their AI implementations, ensuring they choose the right model for each workflow at the best possible cost.
Frequently Asked Questions
Agenta FAQ
What is LLMOps?
LLMOps refers to a set of practices and tools designed to optimize the development and deployment of large language models (LLMs). Agenta embodies LLMOps principles by providing a structured platform for collaboration, experimentation, and observability.
How does Agenta improve collaboration among team members?
Agenta centralizes workflows by integrating prompt management, evaluation, and observability into a single platform. This eliminates silos, allowing developers, product managers, and domain experts to work together more efficiently.
Can Agenta integrate with existing tools?
Yes, Agenta is designed to seamlessly integrate with various frameworks and models, including LangChain and OpenAI. This flexibility allows teams to incorporate Agenta into their existing tech stack without disruption.
Is Agenta suitable for both developers and non-technical users?
Absolutely. Agenta's user interface is designed to empower domain experts and product managers to run evaluations and experiment with prompts without needing to write code. This inclusivity enhances collaboration across diverse team members.
OpenMark AI FAQ
How does OpenMark AI ensure accurate benchmarking?
OpenMark AI ensures accurate benchmarking by using real API calls to test models rather than relying on cached performance numbers. This method provides users with reliable, up-to-date data on each model's performance.
Do I need technical skills to use OpenMark AI?
No, OpenMark AI is designed for users of all technical backgrounds. Its user-friendly interface allows anyone to describe benchmarking tasks in plain language, making it accessible for both developers and non-developers.
What types of models can I benchmark with OpenMark AI?
OpenMark AI supports a large catalog of models, including those from OpenAI, Anthropic, and Google. This extensive support enables users to test a wide range of AI models suited for various tasks and applications.
Is there a free trial available for OpenMark AI?
Yes, OpenMark AI offers free and paid plans, allowing users to start benchmarking without any initial investment. Users can sign in to receive 50 free credits to explore the platform's capabilities.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed to streamline the development of large language model applications. By empowering AI teams to manage prompt experiments, evaluations, and debugging processes, Agenta centralizes workflows that can otherwise become disorganized and inefficient. As users seek alternatives, they often do so for various reasons, including pricing, feature sets, and specific platform requirements that may not be fully met by Agenta. When searching for an alternative, it's crucial to consider factors such as ease of use, integration capabilities, and the specific needs of your team. Look for platforms that offer robust collaboration tools, automated evaluation systems, and comprehensive observability features to ensure a seamless transition and continued success in LLM development.
OpenMark AI Alternatives
OpenMark AI is a robust web application designed for task-level benchmarking of large language models (LLMs). It enables users to test over 100 different models by simply describing their requirements in plain language, allowing for a streamlined comparison of cost, speed, quality, and stability. This tool is tailored for developers and product teams who need to make informed decisions before implementing AI features in their products. Users often seek alternatives to OpenMark AI due to various reasons such as pricing structure, feature sets, and platform compatibility. It's essential to evaluate potential alternatives based on criteria like ease of use, range of supported models, and the ability to deliver consistent results. Consideration of these factors will help you find the best fit for your specific benchmarking needs and project requirements.